Smart Exception Handling in Operations: From Exception Flood to Decision Signal
How mid-market organizations can use practical Operational AI to triage exceptions, reduce noise, and focus leaders and teams on the decisions that actually matter.
Executive Summary: Why Exception Noise Is Now an Operational Risk
Many mid-market organizations are not struggling with a lack of data. They are struggling with too many exceptions.
Alerts, holds, flags, escalations, and manual reviews have multiplied across operations. What were once edge cases have become the daily workload. As a result, teams spend more time sorting issues than resolving them.
The consequences are familiar: slower decisions, rising costs, inconsistent customer experiences, and growing operational risk.
Operational AI triage offers a practical response. By classifying, prioritizing, and routing exceptions inside real workflows, AI helps organizations convert exception floods into decision-ready signals—without over-automation or loss of control.
What Do We Mean by “AI Triage” and “Operational AI”?
Before discussing solutions, it is essential to align on definitions. Many AI initiatives fail not because of technology, but because leaders and teams are solving different problems under the same label.
Definition: Key Terms
- Operational AI — AI capabilities embedded directly into live business workflows to improve the speed, accuracy, and consistency of decisions and actions. This is different from standalone analytics or experimental demos.
- Exception overload — A condition where the volume and variety of exceptions exceeds the organization’s ability to review, route, and resolve them reliably.
- AI opportunity — A specific workflow-level problem where AI can measurably improve an operational metric such as cycle time, cost, error rate, or service quality.
- AI pilot — A controlled deployment of AI in a real workflow with clear scope, KPIs, and human oversight, designed to validate value before scaling.
- Feasibility — The practical likelihood that an AI use case can succeed, given data availability, system integration, governance, and change management readiness.
- Orchestration platform — A workflow layer that connects AI components with systems of record such as ERP, CRM, and ticketing tools, while managing rules, approvals, monitoring, and auditability.
These definitions matter because exception handling is not a modeling problem. It is a workflow and decision design problem.
What Is the Operational Problem and Why Does It Keep Showing Up?
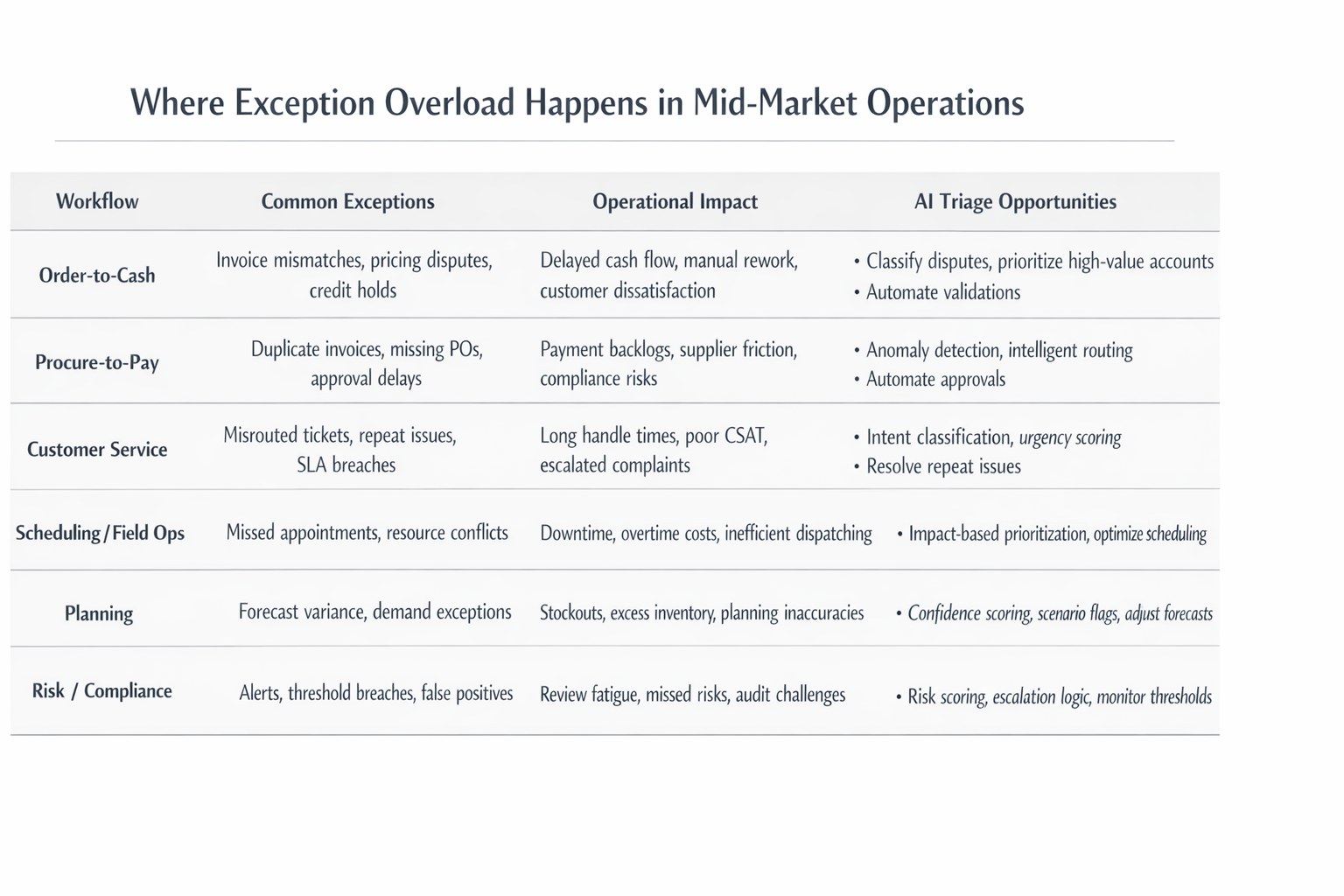
Where Exception Overload Happens in Mid-Market Operations
The Problem Leaders Experience
As organizations grow, exceptions scale faster than processes mature. What once required occasional human judgment becomes a constant stream of interruptions.
Over time, recognizable symptoms emerge:
- Exception queues become permanent backlogs
- Truly critical issues are buried among low-value alerts
- Managers spend more time sorting work than solving problems
- Customer and partner experiences become inconsistent
This pattern is not driven by poor execution or underperforming teams. It is the result of systems that were never designed to triage at scale.
Common Root Causes in Mid-Market Organizations
Exception overload typically stems from a combination of structural issues:
- Alert proliferation — Systems generate large volumes of low-quality alerts with limited context.
- Rule sprawl — Legacy rules create false positives and require constant tuning.
- Siloed systems — Context needed to assess severity is spread across multiple tools.
- Unclear ownership — No single owner is accountable for specific exception categories.
- Capacity mismatch — Transaction volumes grow faster than staffing or workflow redesign.
- Weak governance — Thresholds, escalation criteria, and audit trails are inconsistent.
Typical Workflows Affected
Exception overload commonly appears in:
- Order-to-cash: pricing mismatches, credit holds, delivery delays
- Procure-to-pay: invoice discrepancies, duplicate invoices, vendor setup issues
- Customer service: ticket escalations, SLA breaches, repeat contacts
- Scheduling and field operations: missed appointments, routing changes, parts availability issues
- Planning and compliance: forecast overrides, suspicious activity alerts, documentation gaps
Why Does This Matter Operationally and Financially?
Exception overload is not just frustrating. It is expensive.
Operational Impact
- Throughput loss — Exceptions create hidden work-in-process that slows the entire system
- Longer cycle times — Manual reviews and approvals add days or weeks
- Higher error rates — Rushed decisions lead to downstream rework
- Decision fatigue — Leaders lose focus on issues that truly matter
- Reduced resilience — High-risk events are missed when everything appears urgent
Financial Impact
- Higher cost-to-serve from manual triage and rework
- Slower cash flow due to billing and approval delays
- Revenue leakage from SLA penalties, preventable credits, and churn
- Compliance exposure when high-risk alerts are missed
Deloitte reports that mid-market firms that successfully operationalize AI often achieve both cost reduction and new revenue generation, while those stuck in pilot mode see limited returns.
How Does AI Apply in Practice Without Hype?
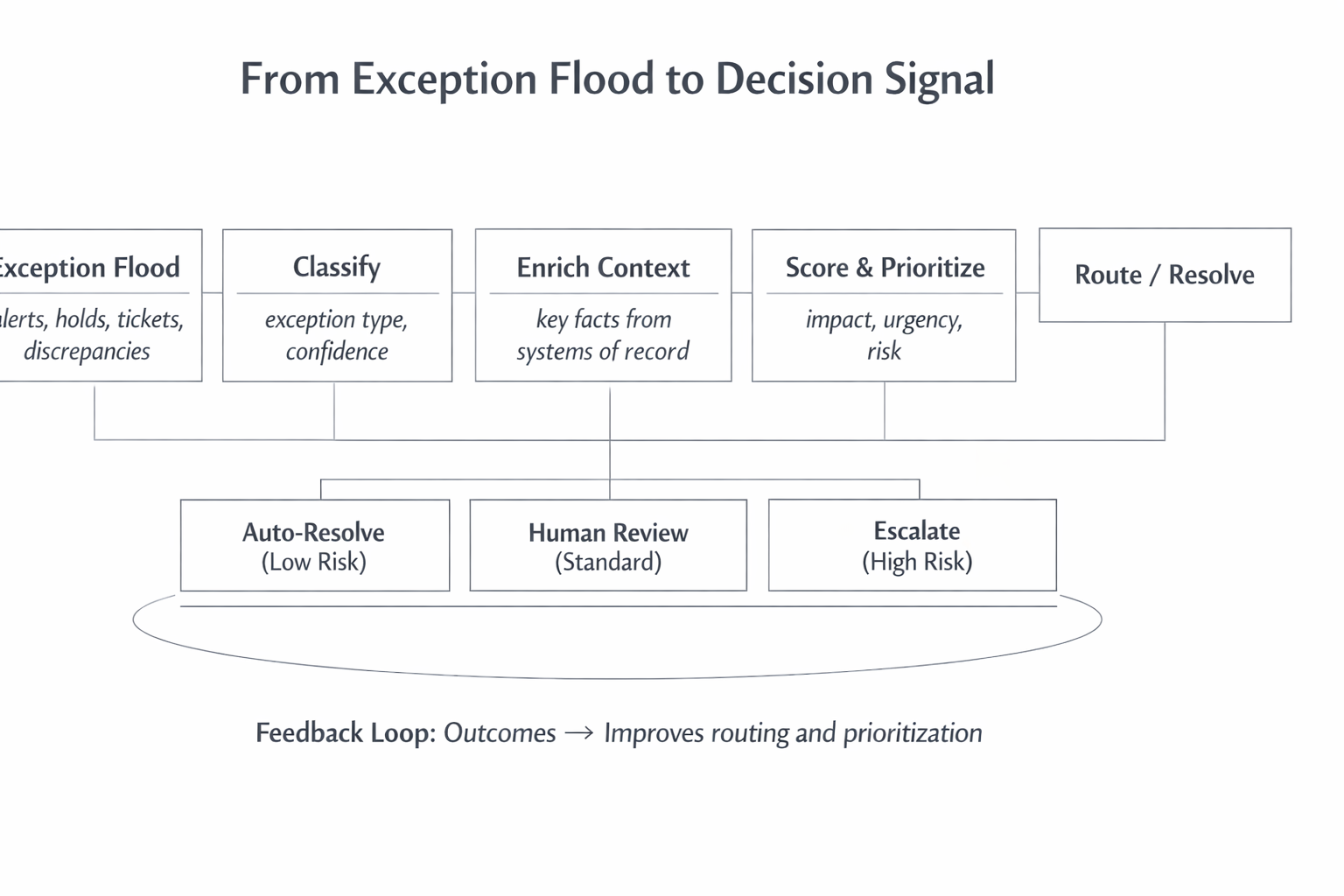
From Exception Flood to Decision Signal
The role of AI in exception handling is not autonomy. It is triage.
What AI Does Well
In practice, AI supports exception handling by:
- Classifying exception types using historical patterns
- Enriching context by pulling relevant data from systems of record
- Scoring urgency, business impact, and risk using explainable factors
- Clustering similar exceptions to reduce repetitive work
- Routing work to the appropriate queue or role
- Recommending next best actions based on prior outcomes
- Learning from resolutions and overrides to improve future triage
These capabilities rely on proven techniques such as classification, anomaly detection, and decision support—not speculative autonomous systems.
What AI Should Not Do
AI should not:
- Take irreversible actions in high-risk scenarios without controls
- Replace accountability for compliance or policy decisions
- Operate without monitoring, audit logs, and escalation paths
When Is AI Triage Not the Right Answer?
AI triage is powerful, but it is not universal.
It may be the wrong approach when:
- Exception volume is low and a single upstream defect is the real issue
- Data is too sparse or inconsistent to separate signal from noise
- Decisions are high-stakes and governance maturity is low
- AI outputs cannot be integrated into systems of record
- The organization lacks capacity for change management
What Does This Look Like in Real Operations?
Example 1: Logistics and Dispatch Operations
A regional logistics provider faced thousands of shipment exceptions each month. Late pickups, address errors, and carrier delays were handled manually, leading to frequent escalations.
After introducing AI triage:
- Exceptions were classified and scored by customer priority and SLA risk
- Similar issues were grouped to reduce repetitive handling
- High-impact issues were routed directly to senior dispatchers
Faster resolution times, fewer escalations, and improved on-time delivery. Industry data shows AI-driven logistics optimization can reduce operating costs by up to 30% while improving service reliability.
Example 2: Healthcare Administration
A mid-sized healthcare network struggled with prior authorization and claims exceptions. Staff spent large portions of the day reviewing missing documentation and resubmitting claims.
With AI triage:
- Missing requirements were extracted automatically from payer communications
- Likely denial risk was identified early
- Work was routed to specialized teams with clear checklists
Reduced rework, faster reimbursement cycles, and lower overtime. Studies estimate administrative simplification using AI could reduce healthcare operating costs by 4 to 10%.
Example 3: Manufacturing and Supply Chain
A manufacturing company experienced frequent supplier delays and order holds that disrupted production schedules.
AI triage helped the organization:
- Prioritize exceptions by production impact
- Recommend actions such as alternate suppliers or rescheduling
- Route issues to procurement, planning, or quality teams
Fewer line stoppages and lower expedite costs. McKinsey estimates predictive and decision-support AI can reduce supply chain disruptions by up to 50%.
How Should Leaders Implement AI Triage Step by Step?
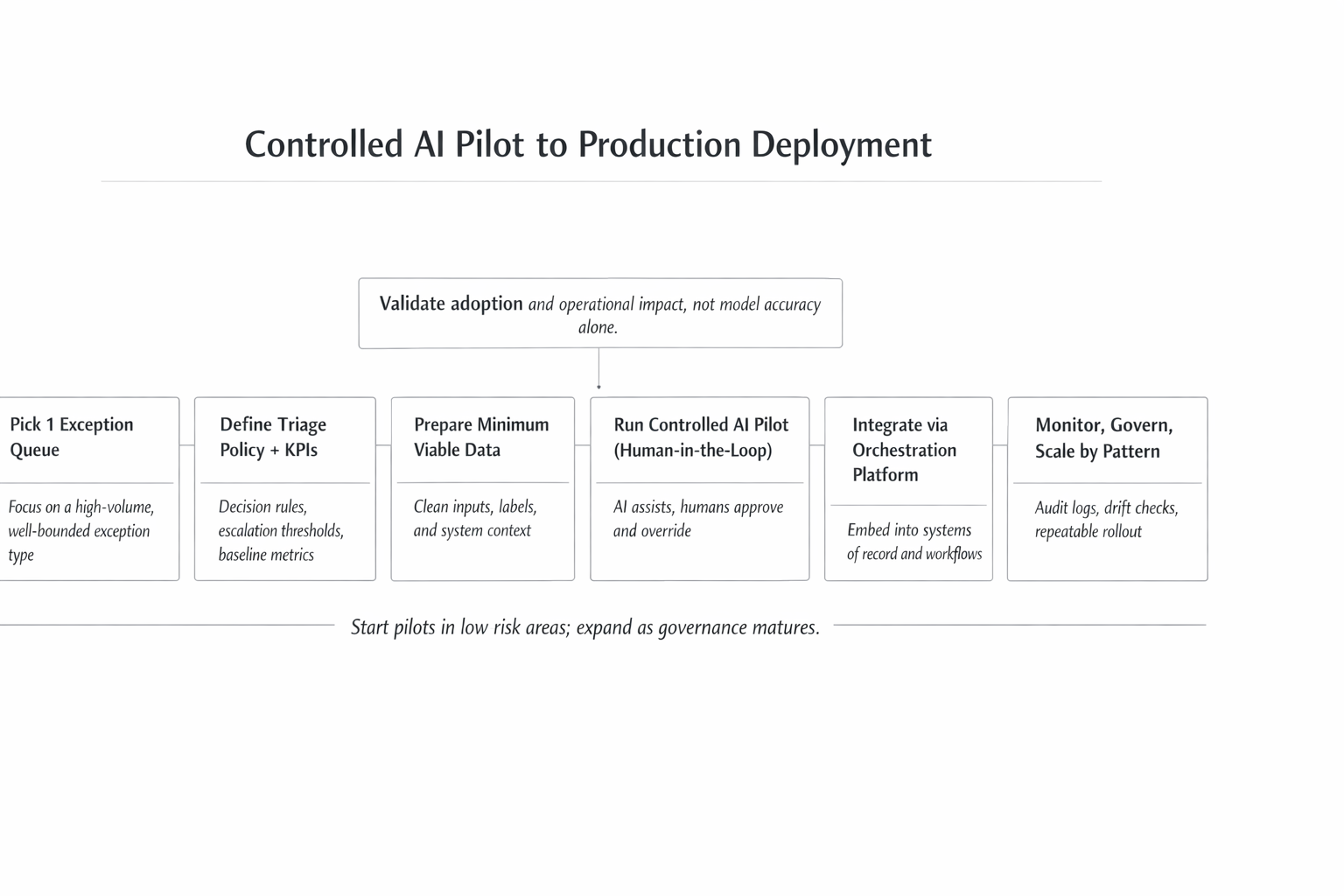
Controlled AI Pilot to Production Deployment
A disciplined implementation approach typically follows these steps:
Select one exception queue
Choose a queue with clear volume and business impact.
Define triage policy and KPIs
Set metrics such as backlog reduction or cycle time improvement.
Prepare minimum viable data
Extract data from existing systems—perfection is not required.
Run a controlled AI pilot
Keep humans in the loop and measure real outcomes.
Integrate via an orchestration platform
Ensure AI outputs trigger real actions in systems of record.
Monitor and scale by pattern
Expand systematically, not through one-off builds.
Organizations that focus on one workflow at a time are far more likely to reach production deployment than those attempting broad AI rollouts.
What Should Leaders Watch Out For?
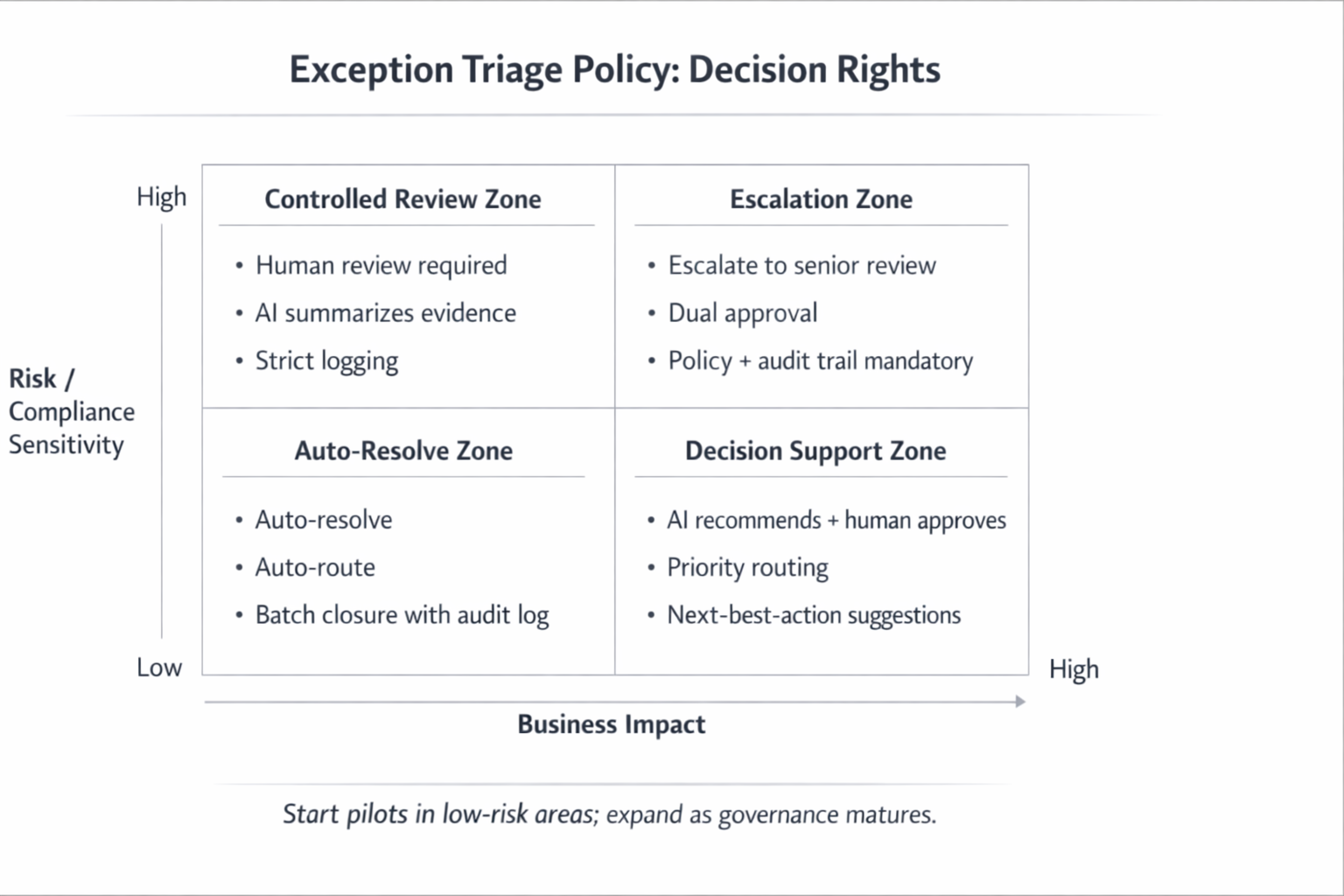
Exception Triage Policy Decision Rights

Common Pitfalls in AI Triage and How to Avoid Them
Common pitfalls include:
- Tool-first thinking instead of workflow-first design
- Over-automation before trust and governance are established
- No clear ownership for exception categories
- Missing baseline metrics
- Siloed deployments disconnected from systems of record
- Lack of monitoring and auditability
Key Takeaways for Business Leaders
- Exception overload is a system design problem, not a staffing problem
- Operational AI triage focuses human effort on high-impact decisions
- Start with one workflow and clear KPIs to avoid pilot stagnation
- AI should assist and prioritize, not replace accountability
- Integration and governance matter more than model sophistication
Executive FAQ
Is AI triage the same as automation?
No. AI triage prioritizes and routes work. Automation may follow, but only where appropriate.
How long does it take to see results?
Many organizations see measurable improvements within 8 to 12 weeks when pilots are tightly scoped.
Do we need perfect data to start?
No. Minimum viable data is often sufficient if outcomes and feedback loops are captured consistently.
Ready to Turn Exception Noise Into Decision Signal?
Sentia Digital helps teams identify high-value exception workflows, assess feasibility, and design pilots that can scale safely into production.
Start an AI Opportunity Assessment →